Informatica PowerCenter 9 Architecture

Before we learn how to use
Informatica, we need to understand what are the important components of
Informatica and how it works.
Informatica tool consists of
following services & components
1.Repository Service – Responsible for maintaining
Informatica metadata & providing access of same to other services.
2.Integration Service – Responsible for the
movement of data from sources to targets
3.Reporting Service - Enables the generation of
reports
4.Nodes – Computing platform where the above
services are executed
5.
Informatica Designer - Used for
creation of mappings between source and target
6.
Workflow Manager – Used to create
workflows and other task & their execution
7.
Workflow Monitor – Used to monitor
the execution of workflows
8.
Repository Manager – Used to manage
objects in repository
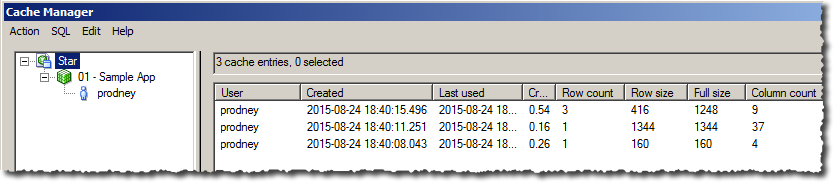
The informatica repository is at the center of the informatica suite.
· The Informatica repository is a
relational database that stores information, or metadata, used by the
Informatica Server and Client tools.
· Metadata is data about data which include
information such as source definitions , target definitions, mappings
describing how to transform source data, sessions indicating when you want the
Informatica Server to perform the transformations, and connect strings for
sources and targets.
· The repository also stores
administrative information such as usernames and passwords, permissions and
privileges, and product version.
· Use
repository manager to create the repository. The Repository Manager connects to
the repository database and runs the code needed to create the repository
tables. These tables stores metadata in specific format the informatica
server, client tools use.
|
The informatica repository is at the center of the informatica suite.
· The Informatica repository is
a relational database that stores information, or metadata, used by the
Informatica Server and Client tools.
· Metadata is data about data which include
information such as source definitions , target definitions, mappings
describing how to transform source data, sessions indicating when you want
the Informatica Server to perform the transformations, and connect strings
for sources and targets.
· The repository also stores
administrative information such as usernames and passwords, permissions and
privileges, and product version.
· Use repository manager to
create the repository. The Repository Manager connects to the repository
database and runs the code needed to create the repository tables. These
tables stores metadata in specific format the informatica server, client
tools use.
Informatica Components:
Server Components:
Client Components:
Server Components 1. Repository Server:
Ø The Repository Server manages
the metadata in the repository database.
Ø The Repository Server manages
connections to the repository from client applications.
Ø The Repository Service is a
separate, multi-threaded process that retrieves, inserts, and updates
metadata in the repository database tables. The Repository Service ensures
the consistency of metadata in the repository.
2. Integration Service:
Ø The Integration Server reads
mapping and session information from the repository. It extracts data from
the mapping sources and stores the data in memory while it applies the
transformation rules that you configure in the mapping. The Integration
Server loads the transformed data into the mapping targets.
Ø Manages the scheduling and
execution of workflows
Ø The Integration Server can
start and run multiple workflows concurrently. It can also concurrently
process partitions within a single session.
|