Model Repository Overview
The Model repository is a relational database that stores the metadata for projects and folders.
Connect to the Model repository to create and edit physical data objects, mapping, profiles, and other objects. Include objects in an application, and then deploy the application to make the objects available for access by end users and third-party tools.
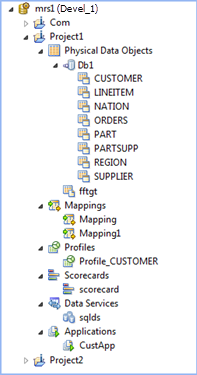
The following image shows an open Model repository named mrs1 in the Object Explorer view:
The Model Repository Service manages the Model repository. All client applications and application services that access the Model repository connect through the Model Repository Service. Client applications include the Developer tool and the Analyst tool. Informatica services that access the Model repository include the Model Repository Service, the Analyst Service, and the Data Integration Service.
When you set up the Developer tool, you must add a Model repository. Each time you open the Developer tool, you connect to the Model repository to access projects and folders.
When you edit an object, the Model repository locks the object for your exclusive editing. You can also integrate the Model repository with a third-party version control system. With version control system integration, you can check objects out and in, undo the checkout of objects, and view and retrieve historical versions of objects.
Use the data quality capabilities in the Developer tool to analyze the content and structure of your data and enhance the data in ways that meet your business needs.
Use the Developer tool to design and run processes to complete the following tasks:
Profile data. Profiling reveals the content and structure of data. Profiling is a key step in any data project as it can identify strengths and weaknesses in data and help you define a project plan.
Create scorecards to review data quality. A scorecard is a graphical representation of the quality measurements in a profile.
Standardize data values. Standardize data to remove errors and inconsistencies that you find when you run a profile. You can standardize variations in punctuation, formatting, and spelling. For example, you can ensure that the city, state, and ZIP code values are consistent.
Parse data. Parsing reads a field composed of multiple values and creates a field for each value according to the type of information it contains. Parsing can also add information to records. For example, you can define a parsing operation to add units of measurement to product data.
Validate postal addresses. Address validation evaluates and enhances the accuracy and deliverability of postal address data. Address validation corrects errors in addresses and completes partial addresses by comparing address records against address reference data from national postal carriers. Address validation can also add postal information that speeds mail delivery and reduces mail costs.
Find duplicate records. Duplicate analysis calculates the degrees of similarity between records by comparing data from one or more fields in each record. You select the fields to be analyzed, and you select the comparison strategies to apply to the data. The Developer tool enables two types of duplicate analysis: field matching, which identifies similar or duplicate records, and identity matching, which identifies similar or duplicate identities in record data.
Manage exceptions. An exception is a record that contains data quality issues that you correct by hand. You can run a mapping to capture any exception record that remains in a data set after you run other data quality processes. You review and edit exception records in the Analyst tool.
Create reference data tables. Informatica provides reference data that can enhance several types of data quality process, including standardization and parsing. You can create reference tables using data from profile results.
Create and run data quality rules. Informatica provides rules that you can run or edit to meet your project objectives. You can create mapplets and validate them as rules in the Developer tool.
Collaborate with Informatica users. The Model repository stores reference data and rules, and this repository is available to users of the Developer tool and Analyst tool. Users can collaborate on projects, and different users can take ownership of objects at different stages of a project.
Export mappings to PowerCenter®. You can export and run mappings in PowerCenter. You can export mappings to PowerCenter to reuse the metadata for physical data integration or to create web services.
The Service Manager is a service that manages all domain operations. It runs within Informatica Services. It runs as a service on Windows . When you start Informatica Services, you start the Service Manager. The Service Manager runs on each node. If the Service Manager is not running, the node is not available.
The Service Manager runs on all nodes in the domain to support the application services and the domain:
Application Services: Application services represent PowerCenter server-based functionality. Here are some application services in Informatica Power Center.
Integration Service
Repository Service
Reporting Service
Metadata Manager Service
SAP BW Service
Web Services Hub
Reference Table Manager Service
Required Services and DB Schemas for 10.1 IDQ Configuration
Required Services are:
Model repository service (MRS)
Data Integration Service
Analyst Service
Content Management Service
Data Director Service
Required database Schemas are :
Database schema for Model repository (for MRS)
Database schema for data profiling (for Analyst service)
IDQ Application Services and Schemas:
List of application services part of the Data Quality Standard Edition:
AnalysServicee
Content Management Service
Data Integration Service
Model Repository Service
Search Service
Set up the following databases:
Model repository for the Model Repository Service.
Data object cache database to cache logical data objects and virtual tables.
Profiling warehouse to perform data profiling and discovery.
Workflow database to store run-time metadata for workflows.
Reference data warehouse to store reference table data for the Content Management Service.
--------------------------------------------------------------------------
Components of Teradata
--------------------------------------------------------------------------
Teradata is made up of following components –
Processor Chip – The processor is the BRAIN of the Teradata system. It is responsible for all the processing done by the system. All task are done according to the direction of the processor.
Memory – The memory is known as the HAND of the Teradata system. Data is retrieved from the hard drives into memory, where processor manipulates, change or alter the data. Once changes are made in memory, the processor directs the information back to the hard drive for storage.
Hard Drives – This is known as the SPINE of the Teradata system. All the data of the Teradata system is stored in the hard drives. Size of hard drives reflects the size of the Teradata system.
Teradata has Linear Scalability
One of the most important asset of Teradata is that it has Linear Scalability. There is no limit on Teradata system. We can grow it to as many times as we want. Any time you want to double the speed of Teradata system, just double the numbers of AMPs and PE. This can be better explained with the help of an example –
Teradata takes every table in the system and spread evenly among different AMPs. Each Amp works on the portion of records which it holds.
Suppose a EMPLOYEE table has 8 different employee id’s. Now in a 2 AMP system each AMP will hold 4 rows in its DISK to accommodate total 8 rows.
At the time of data retrieval each AMP will work on its DISK and send 4 rows to PE for further processing. If we suppose, one AMP will take 1 microseconds (MS) to retrieve 1 rows, then the time taken to retrieve 4 rows is 4 MS. And as we know that AMPs work in parallel, so both the AMPs will retrieve all 8 records in 4 MS only (4 MS time for each AMP).
Now we double the AMP in our system, and we use total 4 AMP. As Teradata distribute the records evenly among all AMPs, so now each AMP will store 2 records of the table.
--------------------------------------------------------------------------
SET or MULTISET tables:-
--------------------------------------------------------------------------
SET tables – SET tables did not allow duplicate values in the table.
MULTISET tables – MULTISET tables allow duplicate values in table.
CREATE VOLATILE TABLE temp
(
ID INT,
Name VARCHAR(20)
)
PRIMARY INDEX(ID)
ON COMMIT PRESERVE ROWS;
insert into test values(1,'DINESH');
insert into test values(2,'LUCK');
---
create index (id) on test1
create unique index (id) on test1
HELP STATISTICS test1
-----------------------------------------------------------
*EXPLAIN command returns the execution plan of parsing engine in English*
EXPLAIN select * from test1
show table test
-----------------------------------------------------------------------------
Built-in Functions in Teradata
-----------------------------------------------------------------------------
-----------------------------------------------------------------------------
How to get Case Sensitivity in Teradata
-----------------------------------------------------------------------------
Teradata by default is case insensitive. Whatever value you compare in the WHERE clause it does not match the exact case of that value.
So what if there is a scenario when you want to compare the value along with its specific case in the WHERE clause. Here come the CASESPECIFIC keyword for the rescue.Just by adding this keyword after the value in WHERE clause we can force the Teradata to impose case sensitivity on the checking condition
select current_date where upper('teradata')='teradata'(CASESPECIFIC);---not return any date.
select current_date where lower('teradata')='teradata'(CASESPECIFIC);---return date.
SELECT emp_name FROM emp_table WHERE emp_name (CASESPECIFIC) LIKE ‘John%’ —— This query will return all name starting with capital J only
So just by using CASESPECIFIC we can force Teradata to check for case sensitivity
--------------------------------------
Primary Index in Teradata-
--------------------------------------
Each table in Teradata is required to have a primary index.Even if you did not define any primary index in CREATE table statement, the Teradata system will automatically create the primary index based on the setting of DBScontrol setting field . The primary index defines where data will reside and which AMP receives the row.
The three most important roles the primary index does is the following –
Data Distribution
Fastest way to retrieve Data
Incredibly important for Joins
In short primary index provides the fastest physical path to retrieving dazta.
2 type:-
A unique primary index means that the value for the selected column must be unique.
A Non unique primary index means that the value for the selected column can be non unique.
The primary index is the key to determine where the ROW of the table will reside on which AMP. When a new row arrive for insert in Teradata the following steps occur –
Teradata Parsing Engine (PE) examines the primary index of the row.
Teradata takes the primary index of the rows and run it through HASHING ALGORITHM.
The output of the Hashing Algorithm is the 32 bit Row – Hash value.
-----------------------------------------------------------------------------
Secondary Index in Teradata:--
-----------------------------------------------------------------------------
Secondary Indexes provide an alternate path to the data, and should be used on queries that run many times.
Syntax of creating Secondary Index
Syntax of UNIQUE SI:
CREATE UNIQUE INDEX (Column/Columns) ON .;
Syntax of NON-UNIQUE SI:
CREATE INDEX (Column/Columns) ON .;
Whenever you create SI on the table, Teradata will create a subtable on all AMP. This subtable contains three columns given below –
Secondary Index Value
Secondary Index Row ID (this is the hashed value of SI value)
Base table Row ID (this is the actual base row id )
-----------------------------------------------------------------------------
Recursive Query in Teradata
-----------------------------------------------------------------------------
Using Recursive query data with in the single table can be scanned multiple times using a single SQL statement.
A recursive query is useful when relationships between data elements exist in multiple iterations. Recursive query consist of two parts a seeding query and a recursive query.
Seeding query provides the initial records for which data needs to be iterated whereas Recursive query part helps in data iteration.
Recursive query syntax :
WITH RECURSIVE < recursive_tablename >
(,,….)
AS
(
UNION ALL
)
1) Recursive_tablename is a derived recursive table defined using WITH RECURSIVE keyword.
2) Column names of recursive table is specified as . This column names will be finally displayed in the output.
3) Seeding query ( query which is used as the input for recursive logic ) is mentioned as the first select statement.
4) Second select statement is known as the recursive query and is joined with seed table for multiple iterations.
5) Third select statement finally gives the output of recursive logic.
-----------------------------------------------------------------------------------------------------------------------
ROLLUP is used to aggregate data along all the levels of hierarchy within a single dimension.
SELECT PRODUCT_ID
,SUM(QUANTITY) AS TOTAL_QUANTITY
FROM STORE_QTY
GROUP BY ROLLUP (PRODUCT_ID)
ORDER BY 1;
roll2
Here along with all Product_Id you get a row which has ? in PRODUCT_ID column.
This ? Isn’t null but instead indicates the grand total of all the product_id.
Top SQL Commands
--------------------------------
--------------------------------
SQL to changing the default Database
Profile Keywords
DATABASE EMP_DATA_BASE;
SQL to find Information about a Database
HELP DATABASE EMP_DATA_BASE;
SQL to get Sample number of rows
SELECT * FROM EMP_TBL SAMPLE 10;
SQL to get a sample Percentage of rows
SELECT * FROM EMP_TBL SAMPLE .50;
SQL to find information about a Table
SHOW TABLE EMP_TBL;
SQL to Use an Access Locked Table
LOCKING ROW FOR ACCESS SELECT * FROM EMP_TBL;
SQL Keywords that describe you
SELECT DATABASE, USER, SESSION,
ACCOUNT,
PROFILE,
ROLE;"
"SELECT DATE,
CURRENT_DATE,
TIME,
CURRENT_TIME,
CURRENT_TIMESTAMP;
SQL to Use Aggregates functions
SELECT TOP 10 STUDENT_NO, FIRST_NAME, LAST_NAME, CLASS_CODE
FROM STUDENT_TBL
ORDER BY GRADE DESC;"
"SELECT DEPT_NO
,MAX(SALARY) AS ""MAXIMUM""
,MIN(SALARY) AS ""MINIMUM""
,AVG(SALARY) AS ""AVERAGE""
,SUM(SALARY) AS ""SUM""
,COUNT(*) AS ""COUNT""
FROM EMP_TBL
GROUP BY DEPT_NO
ORDER BY DEPT_NO;
SQL to Select TOP Rows in a Rank Order
SELECT TOP 10 STUDENT_NO
,FIRST_NAME
,LAST_NAME
,CLASS_CODE
FROM STUDENT_TBL
ORDER BY GRADE DESC;
SQL Using Date, Time and Timestamp
SELECT
CALENDAR_DATE
,DAY_OF_WEEK
,DAY_OF_MONTH
,DAY_OF_YEAR
,DAY_OF_CALENDAR
,WEEKDAY_OF_MONTH
,WEEK_OF_MONTH
,WEEK_OF_YEAR
,WEEK_OF_CALENDAR
,MONTH_OF_QUARTER
,MONTH_OF_YEAR
,MONTH_OF_CALENDAR
,QUARTER_OF_YEAR
,QUARTER_OF_CALENDAR
,YEAR_OF_CALENDAR
FROM SYS_CALENDAR.CALENDAR;
SQL to Find out how much Space a USER have
SELECT
USERNAME
,CREATORNAME
,PERMSPACE
,SPOOLSPACE
,TEMPSPACE
,LASTALTERNAME
,LASTALTERTIMESTAMP
FROM DBC.USERS
WHERE USERNAME='USER';
SQL to find how much Space left Per AMP in database
SELECT
VPROC
,DATABASENAME
,ACCOUNTNAME
,MAXPERM
,MAXSPOOL
,MAXTEMP
FROM DBC.DISKSPACE
WHERE DATABASENAME='EMP_DB' ;
SQL to finding USER Space
SELECT
MAX(MAXPERM)
,MAX(MAXSPOOL)
,MAX(MAXTEMP)
FROM DBC.DISKSPACE
WHERE DATABASENAME='USER' ;
SQL to find Space Skew in Tables in a Database
SELECT VPROC
,CAST(TABLENAME AS CHAR(20))
,CURRENTPERM
,PEAKPERM
FROM DBC.TABLESIZEV
WHERE DATABASENAME='USER'
ORDER BY TABLENAME, VPROC;
SQL to Find Table Skew
SELECT
TABLENAME,
SUM(CURRENTPERM) /(1024*1024) AS CURRENTPERM,
(100 - (AVG(CURRENTPERM)/MAX(CURRENTPERM)*100)) AS SKEWFACTOR
FROM
DBC.TABLESIZE
WHERE DATABASENAME=
AND TABLENAME =
GROUP BY 1;
SQL to Find AMP Skew
SELECT DATABASENAME
,TABLENAME
,VPROC
,CURRENTPERM
,PEAKPERM
FROM DBC.TABLESIZE
WHERE
DATABASENAME=
AND
TABLENAME=
ORDER BY VPROC ;
SQL to find number of rows per AMP for a Column
SELECT HASHAMP(HASHBUCKET( HASHROW(EMP_NO))) AS ""AMP"" , COUNT(*)
FROM EMP_TABLE
GROUP BY 1
ORDER BY 1;
SQL to Identify duplicate records
SELECT COLUMN1, COLUMN2, COLUMN3, COUNT(*)
FROM
DATABASE.TABLE
GROUP BY COLUMN1, COLUMN2, COLUMN3
HAVING COUNT(*) >1;
SQL to Delete Duplicate records
CREATE TABLE TABLE1_BACKUP AS (SELECT * FROM TABLE1 QUALIFY ROW_NUMBER() OVER (PARTITION BY COLUMN1 ORDER BY COLUMN1 DESC )=1) WITH DATA;
DELETE FROM TABLE1;
INSERT INTO TABLE1 SELECT * FROM TABLE_BACKUP;
SQL below to find TOP Databases by space occupied
SELECT
DatabaseName
,MAX(CurrentPerm) * (HASHAMP()+1)/1024/1024 AS USEDSPACE_IN_MB
FROM DBC.DiskSpace
GROUP BY DatabaseName
ORDER BY USEDSPACE_IN_MB DESC;
SQL to find TOP Tables by space occupied
SELECT DATABASENAME
,TABLENAME
,SUM(CurrentPerm)/1024/1024 AS TABLESIZE_IN_MB
FROM DBC.TableSize
GROUP BY DATABASENAME,TABLENAME
ORDER BY TABLESIZE_IN_MB DESC;
SQL to find out list of nodes
SELECT DISTINCT NODEID FROM DBC.RESUSAGESPMA;
SQL to find Account Information
SELECT * FROM DBC.AccountInfoV ORDER BY 1;
Performance Tuning the Siebel Change Capture Process in DAC
DAC performs the change capture process for Siebel source systems. This process has two components:
1)The change capture process occurs before any task in an ETL process runs.
2)The change capture sync process occurs after all of the tasks in an ETL process have completed successfully.
Supporting Source Tables:-
The source tables that support the change capture process are as follows:
S_ETL_I_IMG. Used to store the primary key (along with MODIFICATION_NUM and LAST_UPD) of the records that were either created or modified since the time of the last ETL.
S_ETL_R_IMG. Used to store the primary key (along with MODIFICATION_NUM and LAST_UPD) of the records that were loaded into the data warehouse for the prune time period.
S_ETL_D_IMG. Used to store the primary key records that are deleted on the source transactional system.
Full and Incremental Change Capture Processes:-
The full change capture process (for a first full load) does the following:
Inserts records into the S_ETL_R_IMG table, which has been created or modified for the prune time period.
Creates a view on the base table. For example, a view V_CONTACT would be created for the base table S_CONTACT.
The incremental change capture process (for subsequent incremental loads) does the following:
Queries for all records that have changed in the transactional tables since the last ETL date, filters them against the records from the R_IMG table, and inserts them into the S_ETL_I_IMG table.
Queries for all records that have been deleted from the S_ETL_D_IMG table and inserts them into the S_ETL_I_IMG table.
Removes the duplicates in the S_ETL_I_IMG table. This is essential for all the databases where "dirty reads" (queries returning uncommitted data from all transactions) are allowed.
Creates a view that joins the base table with the corresponding S_ETL_I_IMG table.
Performance Tips for Siebel Sources:-
Performance Tip: Reduce Prune Time Period:-
Reducing the prune time period (in the Connectivity Parameters subtab of the Execution Plans tab) can improve performance, because with a lower prune time period, the S_ETL_R_IMG table will contain a fewer
number of rows. The default prune time period is 2 days. You can reduce it to a minimum of 1 day.
Note: If your organization has mobile users, when setting the prune time period, you must consider the lag time that may exist between the timestamp of the transactional system and the mobile users' local timestamp. You
should interview your business users to determine the potential lag time, and then set the prune time period accordingly.
Performance Tip: Eliminate S_ETL_R_IMG From the Change Capture Process
If your Siebel implementation does not have any mobile users (which can cause inaccuracies in the values of the "LAST_UPD" attribute), you can simplify the change capture process by doing the following:
Removing the S_ETL_R_IMG table.
Using the LAST_REFRESH_DATE rather than PRUNED_LAST_REFRESH_DATE.
To override the default DAC behavior, add the following SQL to the customsql.xml file before the last line in the file, which reads as
. The customsql.xml file is located in the dac\CustomSQLs directory.
TRUNCATE TABLE S_ETL_I_IMG_%SUFFIX
;
INSERT %APPEND INTO S_ETL_I_IMG_%SUFFIX
(ROW_ID, MODIFICATION_NUM, OPERATION, LAST_UPD)
SELECT
ROW_ID
,MODIFICATION_NUM
,'I'
,LAST_UPD
FROM
%SRC_TABLE
WHERE
%SRC_TABLE.LAST_UPD > %LAST_REFRESH_TIME
%FILTER
INSERT %APPEND INTO S_ETL_I_IMG_%SUFFIX
(ROW_ID, MODIFICATION_NUM, OPERATION, LAST_UPD)
SELECT
ROW_ID
,MODIFICATION_NUM
,'D'
,LAST_UPD
FROM
S_ETL_D_IMG_%SUFFIX
WHERE NOT EXISTS
(
SELECT
'X'
FROM
S_ETL_I_IMG_%SUFFIX
WHERE
S_ETL_I_IMG_%SUFFIX.ROW_ID = S_ETL_D_IMG_%SUFFIX.ROW_ID
)
;
DELETE
FROM S_ETL_D_IMG_%SUFFIX
WHERE
EXISTS
(SELECT
'X'
FROM
S_ETL_I_IMG_%SUFFIX
WHERE
S_ETL_D_IMG_%SUFFIX .ROW_ID = S_ETL_I_IMG_%SUFFIX.ROW_ID
AND S_ETL_I_IMG_%SUFFIX.OPERATION = 'D'
)
;
Performance Tip: Omit the Process to Eliminate Duplicate Records :-
When the Siebel change capture process runs on live transactional systems, it can run into deadlock issues when DAC queries for the records that changed since the last ETL process. To alleviate this problem, you need to
enable "dirty reads" on the machine where the ETL is run. If the transactional system is on a database that requires "dirty reads" for change capture, such as MSSQL, DB2, or DB2-390, it is possible that the record
identifiers columns (ROW_WID) inserted in the S_ETL_I_IMG table may have duplicates. Before starting the ETL process, DAC eliminates such duplicate records so that only the record with the smallest
MODIFICATION_NUM is kept. The SQL used by DAC is as follows:
SELECT
ROW_ID, LAST_UPD, MODIFICATION_NUM
FROM
S_ETL_I_IMG_%SUFFIX A
WHERE EXISTS
(
SELECT B.ROW_ID, COUNT(*) FROM S_ETL_I_IMG_%SUFFIX B
WHERE B.ROW_ID = A.ROW_ID
AND B.OPERATION = 'I'
AND A.OPERATION = 'I'
GROUP BY
B.ROW_ID
HAVING COUNT(*) > 1
)
AND A.OPERATION = 'I'
ORDER BY 1,2
However, for situations where deadlocks and "dirty reads" are not an issue, you can omit the process that detects the duplicate records by using the following SQL block. Copy the SQL block into the customsql.xml file
before the last line in the file, which reads as
. The customsql.xml file is located in the dac\CustomSQLs directory.
SELECT
ROW_ID, LAST_UPD, MODIFICATION_NUM
FROM
S_ETL_I_IMG_%SUFFIX A
WHERE 1=2
Performance Tip: Omit the Process to Eliminate Duplicate Records
When the Siebel change capture process runs on live transactional systems, it can run into deadlock issues when DAC queries for the records that changed since the last ETL process. To alleviate this problem, you need to
enable "dirty reads" on the machine where the ETL is run. If the transactional system is on a database that requires "dirty reads" for change capture, such as MSSQL, DB2, or DB2-390, it is possible that the record
identifiers columns (ROW_WID) inserted in the S_ETL_I_IMG table may have duplicates. Before starting the ETL process, DAC eliminates such duplicate records so that only the record with the smallest
MODIFICATION_NUM is kept. The SQL used by DAC is as follows:
SELECT
ROW_ID, LAST_UPD, MODIFICATION_NUM
FROM
S_ETL_I_IMG_%SUFFIX A
WHERE EXISTS
(
SELECT B.ROW_ID, COUNT(*) FROM S_ETL_I_IMG_%SUFFIX B
WHERE B.ROW_ID = A.ROW_ID
AND B.OPERATION = 'I'
AND A.OPERATION = 'I'
GROUP BY
B.ROW_ID
HAVING COUNT(*) > 1
)
AND A.OPERATION = 'I'
ORDER BY 1,2
However, for situations where deadlocks and "dirty reads" are not an issue, you can omit the process that detects the duplicate records by using the following SQL block. Copy the SQL block into the customsql.xml file
before the last line in the file, which reads as
. The customsql.xml file is located in the dac\CustomSQLs directory.
SELECT
ROW_ID, LAST_UPD, MODIFICATION_NUM
FROM
S_ETL_I_IMG_%SUFFIX A
WHERE 1=2
Performance Tip: Manage Change Capture Views
DAC drops and creates the incremental views for every ETL process. This is done because DAC anticipates that the transactional system may add new columns on tables to track new attributes in the data warehouse. If you
do not anticipate such changes in the production environment, you can set the DAC system property "Drop and Create Change Capture Views Always" to "false" so that DAC will not drop and create incremental views. On
DB2 and DB2-390 databases, dropping and creating views can cause deadlock issues on the system catalog tables. Therefore, if your transactional database type is DB2 or DB2-390, you may want to consider setting the
DAC system property "Drop and Create Change Capture Views Always" to "false." For other database types, this action may not enhance performance.
Note: If new columns are added to the transactional system and the ETL process is modified to extract data from those columns, and if views are not dropped and created, you will not see the new column definitions in the
view, and the ETL process will fail.
Performance Tip: Determine Whether Informatica Filters on Additional Attributes
DAC populates the S_ETL_I_IMG tables by querying only for data that changed since the last ETL process. This may cause all of the records that were created or updated since the last refresh time to be extracted.
However, the extract processes in Informatica may be filtering on additional attributes. Therefore, for long-running change capture tasks, you should inspect the Informatica mapping to see if it has additional WHERE
clauses not present in the DAC change capture process. You can modify the DAC change capture process by adding a filter clause for a . combination in the ChangeCaptureFilter.xml file, which
is located in the dac\CustomSQLs directory.
SQL for Change Capture and Change Capture Sync Processes
The SQL blocks used for the change capture and change capture sync processes are as follows:
TRUNCATE TABLE S_ETL_I_IMG_%SUFFIX
;
INSERT %APPEND INTO S_ETL_I_IMG_%SUFFIX
(ROW_ID, MODIFICATION_NUM, OPERATION, LAST_UPD)
SELECT
ROW_ID
,MODIFICATION_NUM
,'I'
,LAST_UPD
FROM
%SRC_TABLE
WHERE
%SRC_TABLE.LAST_UPD > %PRUNED_LAST_REFRESH_TIME
%FILTER
AND NOT EXISTS
(
SELECT
ROW_ID
,MODIFICATION_NUM
,'I'
,LAST_UPD
FROM
S_ETL_R_IMG_%SUFFIX
WHERE
S_ETL_R_IMG_%SUFFIX.ROW_ID = %SRC_TABLE.ROW_ID
AND S_ETL_R_IMG_%SUFFIX.MODIFICATION_NUM = %
SRC_TABLE.MODIFICATION_NUM
AND S_ETL_R_IMG_%SUFFIX.LAST_UPD = %
SRC_TABLE.LAST_UPD
)
;
INSERT %APPEND INTO S_ETL_I_IMG_%SUFFIX
(ROW_ID, MODIFICATION_NUM, OPERATION, LAST_UPD)
SELECT
ROW_ID
,MODIFICATION_NUM
,'D'
,LAST_UPD
FROM
S_ETL_D_IMG_%SUFFIX
WHERE NOT EXISTS
(
SELECT
'X'
FROM
S_ETL_I_IMG_%SUFFIX
WHERE
S_ETL_I_IMG_%SUFFIX.ROW_ID = S_ETL_D_IMG_%
SUFFIX.ROW_ID
)
;
DELETE
FROM S_ETL_D_IMG_%SUFFIX
WHERE
EXISTS
(
SELECT
'X'
FROM
S_ETL_I_IMG_%SUFFIX
WHERE
S_ETL_D_IMG_%SUFFIX.ROW_ID = S_ETL_I_IMG_%SUFFIX.ROW_ID
AND S_ETL_I_IMG_%SUFFIX.OPERATION = 'D'
)
;
DELETE
FROM S_ETL_I_IMG_%SUFFIX
WHERE LAST_UPD < %PRUNED_ETL_START_TIME
;
DELETE
FROM S_ETL_I_IMG_%SUFFIX
WHERE LAST_UPD > %ETL_START_TIME
;
DELETE
FROM S_ETL_R_IMG_%SUFFIX
WHERE
EXISTS
(
SELECT
'X'
FROM
S_ETL_I_IMG_%SUFFIX
WHERE
S_ETL_R_IMG_%SUFFIX.ROW_ID = S_ETL_I_IMG_%SUFFIX.ROW_ID
)
;
INSERT %APPEND INTO S_ETL_R_IMG_%SUFFIX
(ROW_ID, MODIFICATION_NUM, LAST_UPD)
SELECT
ROW_ID
,MODIFICATION_NUM
,LAST_UPD
FROM
S_ETL_I_IMG_%SUFFIX
;
DELETE FROM S_ETL_R_IMG_%SUFFIX WHERE LAST_UPD < %PRUNED_ETL_START_TIME
;
Database Normalisation is a technique of organizing the data in the database. Normalization is a systematic approach of decomposing tables to eliminate data redundancy and undesirable characteristics like Insertion, Update and Deletion Anamolies. It is a multi-step process that puts data into tabular form by removing duplicated data from the relation tables.
Normalization is used for mainly two purpose,
Eliminating reduntant(useless) data.
Ensuring data dependencies make sense i.e data is logically stored.
Normalization Rule
Normalization rule are divided into following normal form.
First Normal Form
Second Normal Form
Third Normal Form
BCNF
First Normal Form (1NF)
As per First Normal Form, no two Rows of data must contain repeating group of information i.e each set of column must have a unique value, such that multiple columns cannot be used to fetch the same row. Each table should be organized into rows, and each row should have a primary key that distinguishes it as unique.
The Primary key is usually a single column, but sometimes more than one column can be combined to create a single primary key. For example consider a table which is not in First normal form
Student Table :
Student
Age
Subject
Adam
15
Biology, Maths
Alex
14
Maths
Stuart
17
Maths
In First Normal Form, any row must not have a column in which more than one value is saved, like separated with commas. Rather than that, we must separate such data into multiple rows.
Student Table following 1NF will be :
Student
Age
Subject
Adam
15
Biology
Adam
15
Maths
Alex
14
Maths
Stuart
17
Maths
Using the First Normal Form, data redundancy increases, as there will be many columns with same data in multiple rows but each row as a whole will be unique.
Second Normal Form (2NF)
As per the Second Normal Form there must not be any partial dependency of any column on primary key. It means that for a table that has concatenated primary key, each column in the table that is not part of the primary key must depend upon the entire concatenated key for its existence. If any column depends only on one part of the concatenated key, then the table fails Second normal form.
In example of First Normal Form there are two rows for Adam, to include multiple subjects that he has opted for. While this is searchable, and follows First normal form, it is an inefficient use of space. Also in the above Table in First Normal Form, while the candidate key is {Student, Subject}, Age of Student only depends on Student column, which is incorrect as per Second Normal Form. To achieve second normal form, it would be helpful to split out the subjects into an independent table, and match them up using the student names as foreign keys.
New Student Table following 2NF will be :
Student
Age
Adam
15
Alex
14
Stuart
17
In Student Table the candidate key will be Student column, because all other column i.e Age is dependent on it.
New Subject Table introduced for 2NF will be :
Student
Subject
Adam
Biology
Adam
Maths
Alex
Maths
Stuart
Maths
In Subject Table the candidate key will be {Student, Subject} column. Now, both the above tables qualifies for Second Normal Form and will never suffer from Update Anomalies. Although there are a few complex cases in which table in Second Normal Form suffers Update Anomalies, and to handle those scenarios Third Normal Form is there.
Third Normal Form (3NF)
Third Normal form applies that every non-prime attribute of table must be dependent on primary key, or we can say that, there should not be the case that a non-prime attribute is determined by another non-prime attribute. So this transitive functional dependency should be removed from the table and also the table must be in Second Normal form. For example, consider a table with following fields.
Student_Detail Table :
Student_id
Student_name
DOB
Street
city
State
Zip
In this table Student_id is Primary key, but street, city and state depends upon Zip. The dependency between zip and other fields is called transitive dependency. Hence to apply 3NF, we need to move the street, city and state to new table, with Zip as primary key.
New Student_Detail Table :
Student_id
Student_name
DOB
Zip
Address Table :
Zip
Street
city
state
The advantage of removing transtive dependency is,
Amount of data duplication is reduced.
Data integrity achieved.
Boyce and Codd Normal Form (BCNF)
Boyce and Codd Normal Form is a higher version of the Third Normal form. This form deals with certain type of anamoly that is not handled by 3NF. A 3NF table which does not have multiple overlapping candidate keys is said to be in BCNF. For a table to be in BCNF, following conditions must be satisfied:
R must be in 3rd Normal Form
and, for each functional dependency ( X -> Y ), X should be a super Key.
How to check if previous command run successful ?
$?
How to get last line from a file ?
tail -1
How to get first line from a file ?
head -1
How to get 3rd element from each line from a file ?
awk '{print $3}'
How to get 2nd element from each line from a file, if first equal FIND
awk '{ if ($1 == "FIND") print $2}'
How to debug bash script
Add -xv to #!/bin/bash
Example
#!/bin/bash –xv
What it means by #!/bin/sh or #!/bin/bash at beginning of every script ?
That line tells which shell to use. #!/bin/bash script to execute using /bin/bash. In case of python script there there will be #!/usr/bin/python
How to get 10th line from the text file ?
head -10 file|tail -1
What is the first symbol in the bash script file
#
What would be the output of command: [ -z "" ] && echo 0 || echo 1
0
What command "export" do ?
Makes variable public in subshells
How to run script in background ?
add "&" to the end of script
What "chmod 500 script" do ?
Makes script executable for script owner
What ">" do ?
Redirects output stream to file or another stream.
What difference between & and &&
& - we using it when want to put script to background
&& - when we wand to execute command/script if first script was finished successfully
Which is the symbol used for comments in bash shell scripting ?
#
What would be the output of command: echo ${new:-variable}
variable
What difference between ' and " quotes ?
' - we use it when do not want to evaluate variables to the values
" - all variables will be evaluated and its values will be assigned instead.
How to list files where second letter is a or b ?
ls -d ?[ab]*
How to remove all spaces from the string ?
echo $string|tr -d " "
How to print all arguments provided to the script ?
echo $*
or
echo $@
How to change standard field separator to ":" in bash shell ?
IFS=":"
How to get variable length ?
${#variable}
How to print last 5 characters of variable ?
echo ${variable: -5}
What difference between ${variable:-10} and ${variable: -10} ?
${variable:-10} - gives 10 if variable was not assigned before
${variable: -10} - gives last 10 symbols of variable
Which command replaces string to uppercase ?
tr '[:lower:]' '[:upper:]'
How to count words in a string without wc command ?
set ${string}
echo $#
Which one is correct "export $variable" or "export variable" ?
export variable
How to remove all spaces from the string ?
echo $string|tr -d " "
What difference between [ $a == $b ] and [ $a -eq $b ]
[ $a == $b ] - should be used for string comparison
[ $a -eq $b ] - should be used for number tests
What difference between = and ==
= - we using to assign value to variable
== - we using for string comparison
Write the command to test if $a greater than 12 ?
[ $a -gt 12 ]
Write the command to test if $b les or equal 12 ?
[ $b -le 12 ]
How to check if string begins with "abc" letters ?
[[ $string == abc* ]]
What difference between [[ $string == abc* ]] and [[ $string == "abc*" ]]
[[ $string == abc* ]] - will check if string begins with abc letters
[[ $string == "abc*" ]] - will check if string is equal exactly to abc*
How to list usernames which starts with ab or xy ?
egrep "^ab|^xy" /etc/passwd|cut -d: -f1
What $! means in bash ?
Most recent background command PID
What $? means ?
Most recent foreground exit status.
How to print PID of the current shell ?
echo $$
How to get number of passed arguments to the script ?
echo $#
What difference between $* and $@
$* - gives all passed arguments to the script as a single string
$@ - gives all passed arguments to the script as delimited list. Delimiter $IFS
How to define array in bash ?
array=("Hi" "my" "name" "is")
How to print the first array element ?
echo ${array[0]}
How to print all array elements ?
echo ${array[@]}
How to print all array indexes ?
echo ${!array[@]}
How to remove array element with id 2 ?
unset array[2]
How to add new array element with id 333 ?
array[333]="New_element"
What is the difference between $$ and $!?
$$ gives the process id of the currently executing process whereas $! shows the process id of the process that recently went into background.
How will you emulate wc –l using awk?
awk ‘END {print NR} fileName’
How will I insert a line “ABCDEF” at every 100th line of a file?
sed ‘100i\ABCDEF’ file1
How will you find the 99th line of a file using only tail and head command?
tail +99 file1|head -1
Print the 10th line without using tail and head command.
sed–n‘10p’file1
How to display the 10th line of a file? head -10 filename | tail -1
How to remove the header from a file? sed -i ‘1 d’ filename
How to remove the footer from a file? sed -i ‘$ d’ filename
Write a command to find the length of a line in a file? We will see how to find the length of 10th line in a file sed -n ’10 p’ filename|wc -c
How to get the nth word of a line in Unix? cut –f -d’ ‘
How to reverse a string in unix? echo “java” | rev
How to get the last word from a line in Unix file? echo "unix is good"|rev|cut -f1 -d' '
How to replace the n-th line in a file with a new line in Unix? sed -i” ’10 d’ filename # d stands for delete sed -i” ’10 i new inserted line’ filename # i stands for insert
How to check if the last command was successful in Unix? echo $?
Write command to list all the links from a directory? ls -lrt | grep “^l”
How will you find which operating system your system is running on in UNIX? uname -a
Create a read-only file in your home directory? touch file; chmod 400 file
How do you see command line history in UNIX? history
How to display the first 20 lines of a file? head -20 filename or sed ’21,$ d’ filename The d option here deletes the lines from 21 to the end of the file
Write a command to print the last line of a file?
tail -1 filename or sed -n ‘$ p’ filename or awk ‘END{print $0}’ filename
How do you rename the files in a directory with _new as suffix? ls -lrt|grep ‘^-‘| awk ‘{print “mv “$9” “$9″.new”}’ | sh
Write a command to convert a string from lower case to upper case? echo “apple” | tr [a-z] [A-Z]
Write a command to convert a string to Initcap echo apple | awk ‘{print toupper(substr($1,1,1)) tolower(substr($1,2))}’
Write a command to redirect the output of date command to multiple files? The tee command writes the output to multiple files and also displays the output on the terminal. date | tee -a file1 file2 file3
List out some of the Hot Keys available in bash shell?
Ctrl+l – Clears the Screen. Ctrl+r – Does a search in previously given commands in shell. Ctrl+u – Clears the typing before the hotkey. Ctrl+a – Places cursor at the beginning of the command at shell. Ctrl+e – Places cursor at the end of the command at shell. Ctrl+d – Kills the shell. Ctrl+z – Places the currently running process into background.
How do you remove the first number on 10th line in file? sed ’10 s/[0-9][0-9]*//’ < filename
How do you display from the 5th character to the end of the line from a file? cut -c 5- filename
Write a command to search for the file ‘map’ in the current directory? find -name map -type f
Write a command to remove the first number on all lines that start with “@”? sed ‘\,^@, s/[0-9][0-9]*//’ < filename
How to display the first 10 characters from each line of a file? cut -c -10 filename
Write a command to find the total number of lines in a file? wc -l filename or awk ‘END{print NR}’ filename
How to duplicate empty lines in a file? sed ‘/^$/ p’ < filename
How to remove the first 10 lines from a file? sed ‘1,10 d’ < filename
Write a command to duplicate each line in a file? sed ‘p’ < filename
How to extract the username from ‘who am i’ comamnd? who am i | cut -f1 -d’ ‘
How to remove blank lines in a file? grep -v ‘^$’ filename >new_filename
Write a command to display the third and fifth character from each line of a file? cut -c 3,5 filename
Write a command to print the fields from 10th to the end of the line. The fields in the line are delimited by a comma? cut -d’,’ -f10- filename
How to replace the word “Gun” with “Pen” in the first 100 lines of a file? sed ‘1,00 s/Gun/Pen/’ < filename
How to print the squares of numbers from 1 to 10 using awk command awk ‘BEGIN { for(i=1;i<=10;i++) {print “square of”,i,”is”,i*i;}}’
Write a command to remove the prefix of the string ending with ‘/’. basename /usr/local/bin/file This will display only file
How to replace the second occurrence of the word “bat” with “ball” in a file? sed ‘s/bat/ball/2’ < filename
How to replace the word “lite” with “light” from 100th line to last line in a file? sed ‘100,$ s/lite/light/’ < filename
How to list the files that are accessed 5 days ago in the current directory? find -atime 5 -type f
How to list the files that were modified 5 days ago in the current directory? find -mtime 5 -type f
How to list the files whose status is changed 5 days ago in the current directory? find -ctime 5 -type f
How to replace the character ‘/’ with ‘,’ in a file? sed ‘s/\//,/’ < filename sed ‘s|/|,|’ < filename
Write a command to display your name 100 times
The Yes utility can be used to repeatedly output a line with the specified string or ‘y’. yes | head -100
The fields in each line are delimited by comma. Write a command to display third field from each line of a file? cut -d’,’ -f2 filename
Write a command to print the fields from 10 to 20 from each line of a file? cut -d’,’ -f10-20 filename
Write a command to replace the word “bad” with “good” in file? sed s/bad/good/ < filename
Write a command to print the lines that has the word “july” in all the files in a directory and also suppress the
filename in the output. grep -h july *
Write a command to print the file names in a directory that does not contain the word “july”? grep -L july * The ‘-L’ option makes the grep command to print the filenames that do not contain the specified pattern.
Write a command to print the line number before each line? awk ‘{print NR, $0}’ filename :set nu
Write a command to display todays date in the format of ‘yyyy-mm-dd’?
The date command can be used to display today’s date with time date ‘+%Y-%m-%d’